
LLM'ler Nasıl Çalışıyor?
Büyük dil modellerini anlamak için Karpathy'nin videolarını izledim, öğrendiklerimi sizlerle paylaşıyorum.

Mesleğimi elimden alma ihtimali herkesin dilinde olan bu gizemli canavarı yakından tanımak istedim. Teknik bir konu ama basit yazmaya gayret ettim. Cevap aradığım soru şu:
Yapay zeka (LLM) neye benziyor, mimarisi itibarıyla nelerde iyi, nelerde kötü ve bu iş daha nerelere gidebilir?
Bu sorulara cevap arayan biri için Andrej Karpathy’den daha iyi bir kaynak yoktur.
Karpathy kim?
Yazının çıkış noktası, Andrej Karpathy’nin “ChatGPT benzeri LLM’lere detaylı bakış” videosunu izleyip çok beğenmem ve sizinle paylaşmak istemem. Burayı okuyup bu bana yeter demeyin. 3 saatlik bir video. Yazılımla uğraşıyorsanız veya bu konulara meraklıysanız bundan daha iyi bir içerik bulmanız zor. Mutlaka izleyin.
Karpathy için kısa bir tanıtım yapayım. Şu an Antrophic’te çalışıyor. Anthropic’e geçtiğini duyurduğunda yer yerinden oynamıştı. Geçmişte Tesla ve OpenAI’da çalışmış. Çekoslovakya doğumlu bir göçmen. Doktorasını MIT’de yapay zeka üzerine yapmış. Zor konuları basitçe anlatmakta usta. Kafası zaten zehir gibi. Kendisini mutlaka takip edin. YouTube kanalına abone olun, eski videolarına bakın. Pişman olmazsınız.

Video güncel mi?
Kısa cevap: evet güncelliğini koruyor.
Video 5 Şubat 2025’te eklenmiş. Son bir yılda o günden beri çok büyük atılımlar oldu. Özellikle 2025’in sonlarına doğru coding agent’lar aldı başını yürüdü. Ama LLM dediğimiz şey özünde değişmedi, çalışma mantığı aynı. İlk duyuruldukları 2018’lerden beri temel bir farklılık gelmedi. Ama modeller büyüdü, ince ayarları daha güzel yapılmaya başlandı ve tabii üzerinde eğitildikleri veri miktarı ve kalitesi arttı.
Bu yazıyı yazarken Antrophic yeni modeli olan Fable 5’i duyurdu. Şu an Twitter’da herkes bu modelin uçup kaçtığından bahsediyor. Ama arkada nasıl bir yapı olduğunu anlayınca taşlar yerine daha iyi oturuyor ve bu gibi yeni modellerden neler beklemeliyiz daha netleşiyor.
Özetle, bir yıl bu günlerde uzun gibi görünse de, LLM’ler çok değişmedi ve birazdan öğreneceğiniz yapılar halen kullanımda.

LLM Mimarisi
LLM’ler üç temel parçaya sahip. Karpathy bu üç temel parçayı, ders kitapları örneği üzerinden şöyle izah ediyor:
Konu anlatımı: İlk aşamada dünyadaki bütün kitapları modele ezberlettiğinizi düşünün. Buna pre-training deniyor. Inference (çıkarım) kavramı bu aşamayı ilgilendiriyor.
Örnek çözümlere çalışmak: İkinci aşamada, çeşitli problemler ve sorulara uzmanlarca verilen cevaplar modele öğretiliyor. Bir nevi çözümlü problemler kitabına çalışmak gibi. Bu aşama post-training, ya da supervised fine-tuning (SFT) olarak adlandırılıyor.
Kendi kendine problem çözmek: Modele problemi ve cevap anahtarını verdiğinizi düşünün. Çözüme kendisi gitmek zorunda. Buna da reinforcement learning (RL) deniyor.
Her adımı tek tek detaylıca inceleyeceğiz. İlk ve en büyük parçayla başlıyoruz.
1. Adım: Inference (Çıkarım)
İster ChatGPT olsun ister Gemini veya başka bir ürün, LLM dediğimiz modeller matematiksel birer ifade.
e^(3x + 5y) - 6z …
Yukarıdaki ifade gibi. Fakat çok daha fazla parametreye sahip (mesela GPT 5.5’te 10 trilyon parametre olduğu söyleniyor). Parametreleri denklemdeki katsayılar olarak düşünün (3, 5, -6). LLM’e verdiğimiz girdi önce “tokenization” denilen işleme tâbi tutuluyor ve kodlanarak rakamlara dönüştürülüyor. Mesela diyelim ki “Merhaba Merhaba Merhaba” yazdık, bu şöyle kodlanıyor
200264, 1428, 200266, 18280, 129766, 9708, 129766, 9708, 129766, 200265, 200264, 173781, 200266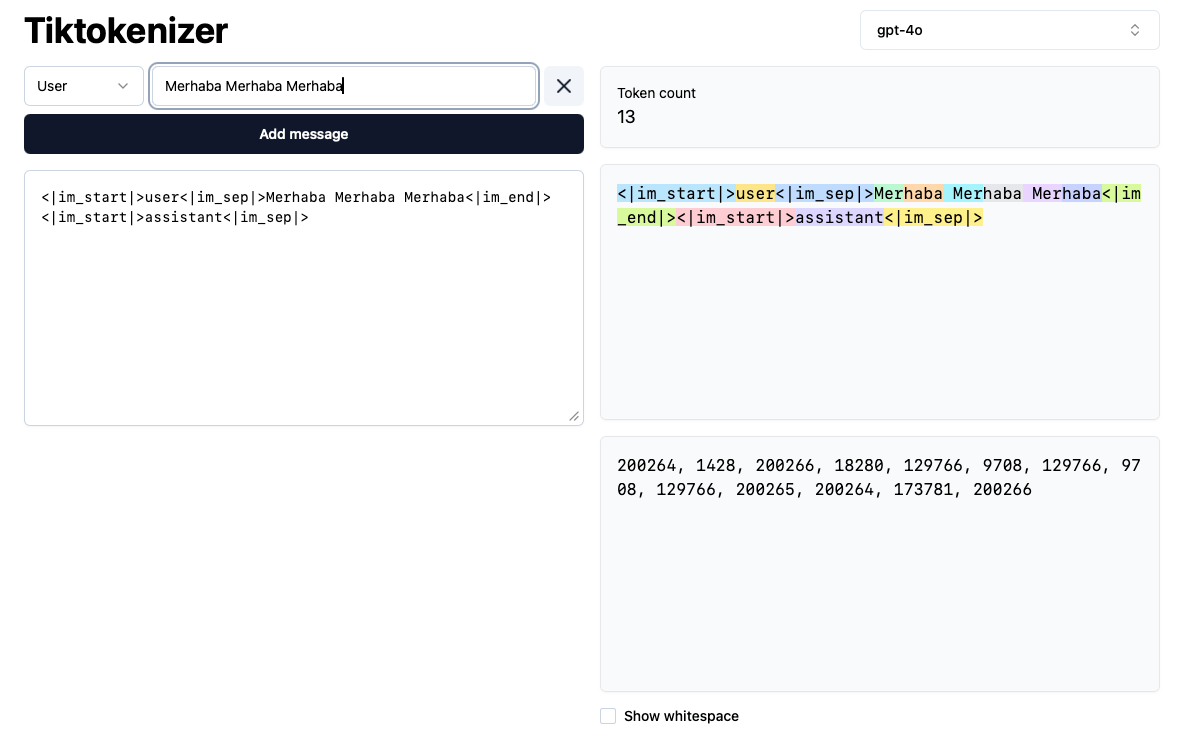
Dikkat ettiyseniz “9708” sayısı iki kere tekrar etmiş (“ “, “M”, “e”, “r“ dizisini kodluyor ve bu dizi iki kere geçiyor verdiğimiz girdide)
Araya sisteme özel token’lar da enjekte ediliyor (im_start, im_end vb.) ve bu sayı dizisi modeli temsil eden ifadeye girdi olarak yerleştiriliyor. Peki bu modeller çıktı olarak ne üretiyor? Çıktı olarak bir sonraki token’ın hangi token olması gerektiğinin olasılıklarını üretiyor. Bu ne demek? Her LLM'in bir token dağarcığı var: kaç farklı token tanıyıp bildiği. Mesela ChatGPT’nin 200.000 tokenlık bir dağarcığı var. Model her çalıştığında 200.000 adet olasılık üretiyor ve daha sonra bu olasılıkların ağırlıklarını dikkate alarak rastgele bir örnekleme yapıp size bir sonraki token’ın ne olduğunu söylüyor. Hileli bir zar attığını düşünün, hilesi de şu: eğitildiği datayı taklit etmeye meyilli.
Basit bir örnek üzerinden göstermek gerekirse, diyelim ki sadece 5 token’lık bir dağarcığı olan hayali bir model olsun. Token’lar 1, 2, 3, 4 ve 5 olsun. Çıktı olarak şöyle bir şey göreceğiz:
[0.1, 0.05, 0.3, 0.15, 0.4]
Olasılıklar toplamı 1’e eşit ve bu olasılık dağılımını örneklediğimizde ortalamada her 10 örnekten 4 tanesinde cevap olarak “5” token’ını verecek model bize. Ya da her 20 örnekten sadece bir tanesinde “2” token’ını göreceğiz (0.05 olaslığa sahip). Eğer 200.000’lik bir token havuzuna sahipse, her seferinde 200.000 adet olasılık üretmiş olacak.
LLM nedir sorusuna verilecek en kısa yanıt: Bir sonraki token’ı tahminleyen matematiksel bir model.
Neden Tokenization Yapılıyor?
Token dediğimiz şeyleri birer ID gibi düşünün, bir nevî kimlik. Bir veya birkaç harf veya karakter grubunun kimliği. Ama neden böyle bir şeye ihtiyaç duyulmuş? Çünkü matematiksel ifadeye girdi olarak sayılar vermek zorundayız. Dolayısıyla yazıları bir şekilde sayılara çevirmemiz gerekiyor.
“Peki tamam burayı anladık da, neden token’lar yerine harfleri veya kelimeleri kullanmamışlar” diye düşünebilirsiniz. “Merhaba” sözcüğüne bu haliyle bir kimlik verilseydi, bu kelimenin bütününe denk gelen token 1234 gibi bir sayı olsaydı. Ya da tam tersi, her bir harfe ayrı ayrı kimlik verseydik ve “M” 1, “e” 2, “r” 3 şeklinde gitseydi. Neden bu iki şekilde değil de rastgele gibi görünen ve tek başına anlamları olmayan harf kümeleri olarak tokenization yapılıyor? Çünkü;
Eğer her harf bir token olsaydı, LLM’lere verdiğimiz girdiler çok uzun serilere dönüşmek zorunda kalacaktı ve bu da “context window”un çabucak dolmasına yol açıp modeli zayıflatacaktı. Her bir karakterin kendi kimliği olduğunu düşünün, en kısa yazı bile bir sürü kimlik temsil eden upuzun bir diziye dönüşecekti.
Eğer her kelime bir token olsaydı, en ufak bir yanlış yazım veya enteresan harf kombinasyonları LLM tarafından kodlanamayacaktı, farklı dillerdeki kelimeleri temsil etmek için her dile özel tokenlar koymak gerekecekti.
Bu sebeplerle, pratikte iki problemi de çözecek biçimde, token’lar kendi başlarına anlam ifade etmeyebilen harf grupları olarak ayarlanıyor.
Context window
Yukarıda lafı geçmişken hemen açıklayayım. Bağlam penceresi olarak çevirebiliriz Türkçe’ye. LLM’in bir seferde girdi olarak alabildiği en uzun token serisinin uzunluğu olarak düşünün. Genelde 100.000 ila 1.000.000 civarlarında bir değer oluyor ve her model için bu sabit. Bu uzunluğun büyük bir kısmı girdi olarak verilen token’lara tahsis ediliyor ve kalanı da çıktı olarak gelen token’lara ait oluyor. Biz mesela ChatGPT ile konuşmaya devam ettikçe, context window’u yavaş yavaş dolduruyoruz. Hem bizim yazdıklarımız hem onun çıktıları birleşip bir sonraki iterasyonda girdi olarak veriliyor ve böyle böyle bağlam penceresi dolmaya başlıyor.
Bağlam penceresi ne kadar geniş olursa, model o kadar büyük bir hafızaya sahip oluyor gibi düşünebilirsiniz. Bağlam penceresini aştığımızda ise, eskiden yazdığımız yazılar artık hafızadan silinmeye başlıyor. Sohbete yeni başladığımızda ise context window boş oluyor (gerçekte tamamen boş değil, sistem komutları ve bize çaktırmadan girilen başka verilerle de beslenmiş oluyor, bize daha iyi bir deneyim sunmak adına).
Bir önceki konuya, tokenization’a bağlayacak olursak (tekrar hatırlamış olalım) eğer her harf bir token’a denk gelseydi context window çok daha çabuk dolacaktı.
Pre-training
LLM modelleri geliştirirken en uzun süren safha pre-training dediğimiz aşama. Bu aşamada modellerdeki (o karmaşık matematiksel ifade) parametreler rastgele değerlerle başlatılıyor ve sonrasında devasa veri setleriyle parametreler ayarlanıyor. Yani aslında pre-training esnasında model, üzerinde eğitildiği veriyi taklit etmesini sağlayacak parametrelere yakınsatılmaya çalışılıyor. Pre-training çok büyük veriler üzerinden yapıldığı için muazzam bir hesaplama kapasitesi (binlerce GPU) ve çok uzun zaman gerektiriyor. Genelde aylar sürüyor bu aşama. Ve neticesinde modeldeki parametreler belirlenmiş oluyor. Model, eğitildiği veriye istatistiksel olarak benzer çıktılar üretebilir hale geliyor.
Modeldeki matematiksel ifade
Hep “matematiksel ifade” diyip diyip geçiştirdim. Neden derseniz, işin bu kısmı bizim için biraz kara kutu gibi. Burada “transformers” denilen bir mimari kullanılıyor ve matematiksel ifadenin de elbette belli nüansları ve hassasiyetleri oluyor. Bu, modelin öğrenme şeklini ve yeteneklerini belirleyici bir faktör. Video bu konuda detaya girmiyor. Zaten oldukça derin ve uzmanlık gerektiren bir konu. Maxwell denklemlerini düşünün (düşünemedi), ben fizik dersini o noktada kapatmıştım. Burada da maalesef kendi adıma algılayabileceğim son noktaya gelmiş oluyorum. Algılayabildiklerimizden devam edelim biz.
2. Adım: SFT (Asistanlaştırma)
Şimdiye kadar gördüğümüz kısım “next token prediction” yani bir sonraki harf dizisinin tahminlenmesiydi. Bu kendi başına ne işe yarar, mesela bir hikayeye başlarsınız LLM sizin için devamını getirir. Ama LLM’e bir soru sorduğunuzda soruya cevap alamazsınız, büyük ihtimalle sorunuza yeni sorular ekleyerek üretmeye devam eder. Çünkü LLM’i ona asistanlık rolünü verecek eğitimden henüz geçirmedik.
SFT, supervised fine-tuning’ing kısaltması. Yani modeli gözetim altında vermesini istediğimiz biçimde cevaplar verecek şekilde eğitmek. Bu iş için görevlendirlen insanlar var, kendi kendine otomatik yapılan bir iş değil.
Bu aşama “post-training” olarak da adlandırılıyor, modele temel eğitimi sonrası bir uzmanlık vermek gibi düşünebilirsiniz. Çok daha kısa sürüyor ve insanlardan yardım alınıyor. Modeli internetten toplanan verilerle eğitmek yerine, firmalar bu aşamada belirledikleri kişilere diyaloglar yazdırıyor. Şöyle veri setleri oluşturuluyor:
İnsan: 2 + 2 kaç eder?
Asistan: 2 + 2 = 4İnsan: İstanbul’da nereleri ziyaret etmeliyim?
Asistan: İstanbul’a gelirseniz, Topkapı Sarayı’nı, Ayasofya Camii’ni ve Galata Kulesi’ni mutlaka görün.
İnsan <> asistan arasında geçiyormuş gibi üretilen diyaloglarla model tekrar eğitiliyor ve parametreler model sanki asistanmış gibi cevap versin diye “fine-tune” ediliyor (ince ayar çekiliyor).
Tekrar hatırlatmak gerekir ki, bu aşama “pre-training” aşamasından çok daha ucuza mal oluyor ve çok daha kısa sürüyor çünkü üzerinde eğittiğimiz veri seti çok daha küçük. Post-training için genelde ucuz iş gücünün olduğu ülkelerden insanlara para verip onlardan istifade ediyor firmalar.

LLM mimarisini düşündüğünüzde, modele insan gibi düşünebilmeyi öğretmek istiyorsanız, öğrettiğiniz çözüm yolları da insanların takip edeceği türden yollar olmalı. Şu problemi ele alalım:
Pazardan 2 kilo elma ile 3 kilo patates aldım ve toplam 110 TL ödedim. Elmanın kilosu 25 TL olduğuna göre, patatesin kilosu kaç TL’dir?
Kötü cevap örneği:
Cevap: bir kilo patates 20 TL. Çünkü 2 kilo elma 50 TL eder. Dolayısıyla 3 kilo patates 60 TL dir. Bu durumda bir kilo patates 60 / 3 = 20 TL.
Kötü örnekte fark ettiyseniz direkt cevapla başladık. Ama LLM’in tek boyutlu token dünyasında tek seferde neticeye varma ihtimali yok. Cevaptan başlamak, modelin eğitimi açısından mantıksız. Çünkü benzer problemi farklı sayılarla çözdürdüğümüzde ona öğrettiğimiz gibi hemen cevabı söyleyerek başlamak isteyecek. Ama cevabı hesaplamadığı için halüsinasyon görecek. Elbette burada hesaplamadan kastımız aslında hesaplama taklidi yapmak. Modele o taklidi yapmayı öğretmediğimizden çuvallayacak. Şimdi iyi bir cevap örneğine bakalım:
İyi cevap örneği:
2 kilo elma ve 3 kilo patates toplam 110 TL tutmuş. Patatesin kilosunu bulabilmem için öncelikle elmaya toplam kaç para ödediğimi hesaplamalıyım. Elmanın kilosu 25 TL ve 2 kilo elma almışım. Bu durumda 2 x 25 = 50 TL eder. Toplam 110 TL ise, bundan elmanın fiyatını çıkardığımda 110 - 50 = 60 TL eder. Üç kilo patates almıştım. Üç kilo patates 60 TL ise, 1 kilo patates 60 / 3 = 20 TL eder. Cevap: bir kilo patates 20 TL.
Eğer modelin bu tarz problemleri çözebilmesini istiyorsak, eğittiğimiz cevaplar çözüme nasıl ulaştığımızı adım adım gösteren türden olmalı. Bu örnekte olduğu gibi. Aslında biz modele dört işlem öğretmiyoruz. Zaten modelin sayılardan haberi bile yok. Onun için sadece “token”lar var. Dolayısıyla biz eğitmek için kullandığımız cevaplarda ne kadar detaya inersek, model de çözüm yolunu parametrelerinde o kadar detaylı biçimde kodlamış olacak. Ona bu fırsatı vermek için bu şekilde cevaplarla eğitmek şart.
3. Adım: Reinforcement learning (Testlere tâbi tutuyoruz)
Bu aşamada artık model asistanmış gibi davranmayı öğrendi. Tüm interneti de zaten ilk adımda yalayıp yutmuş ezberlemişti. Şimdi ise modele son bir ince ayar daha çekiyoruz ve modeli cevabı bilinen konularda sınava tâbi tutuyoruz.
2. adımdan farklı olarak, burada problemlerin çözümlerini öğretmiyoruz. Problemleri modele defalarca çözdürüyoruz. Cevaplarını gerçek cevaplarla karşılaştırıyoruz ve doğru cevaplara giden yolları ödüllendirip, yanlış cevaba götüren yolları cezalandırıyoruz. Böylece doğru çözdüğü çözüm yöntemlerinin pekiştirilmesini (reinforcement) sağlıyoruz. Yanlış çözdüğü çözüm yollarını da cezalandırdığımızdan, modeli bir daha o yoldan gitmemesi için caydırmış oluyoruz. Bu aşamada herhangi bir insan dahil olmuyor sürece, tamamen otomatik olarak yapılıyor “reinforcement learning” aşaması.

Strawberry kelimesinde kaç “r” harfi var?
3 tane var değil mi? Bir ara LLM’ler bu soruya acayip halüsinasyonlu cevaplar veriyordu. Çünkü soruyu tokenlara çevirdiğiniz an “r” diye bir harf kalmıyor, misal “Stra”, “wbe”, “rry” şeklinde tokenize edilyor. Model tek tek harf görmediği için sayamıyor. Bu arada, tek tek harf görse bile sayamazdı. Çünkü modeller aritmetik yapmıyor, istatistiksel olarak bir sonraki token’ı tahmin ediyor. Fakat yeni modeller bu tarz soruları da içerecek şekilde eğitildiklerinden artık pek halüsinasyon görmüyorlar. Ama bu demek değil ki kelime kavramına veya aritmetik yeteneğine sahipler.
Karpathy videosunda bu tarz sorular için modele “tool use” yapmasını söylüyor ve bu sayede model bir kelimedeki “r” harfini sayan Python kodunu üretip Python interpreter üzerinden “Strawberry” kelimesini de girdi olarak vererek kodu çalıştırıp kesin cevabı veriyor. Modellerin zayıf oldukları noktaları bilip, ona göre yönlendirme yapmak gerekiyor.
Modellerin bir başka eksikliği de güncel bilgiye sahip olmamaları. Dikkat ederseniz model duyurularında bir “cut-off” tarihinden bahsediliyor. Bu tarih bize modelin eğitildiği datanın hangi tarihe kadar olduğunu söylüyor. Mesela 31-12-2025 cut-off’una sahip bir modele ABD - İran savaşını sorsanız bilemez. Bu durumda model internet aramasına yönelebilir ve güncel bilgiyi oradan çekebilir. Ama modelin içerisinde bu bilgi yoktur. O yüzden mesela bir kitap özeti yaptıracaksanız, modele kitabın tamamını girdi olarak verip sonra özetlemesini isterseniz daha başarılı sonuçlar alırsınız. Aksi takdirde belki o kitap eğitim datasında yoktur veya sadece bir bölümü vardır ve alacağınız özet bol halüsinasyonlu olabilir.
Kapanış
3 saatlik bir videoyu özetlemeye çalıştım. Umarım anlaşılır olmuştur. Ama eğer anlamadıysanız, videoyu mutlaka izleyin. Görsel öğelerle de destekleyerek tane tane anlatıyor.
Bütün bunlardan benim anladığım şu:
LLM dediğimiz şey sonraki token tahmincisi ve eğitim verisi taklitçisi.
Çok büyük veri üzerinden eğitilmişler ve bu veriyi taklit edebilme yetenekleri çok iyi.
Eğer ihtiyaç duyduğunuz şey önceden çözülmüş problemlerse, LLM’ler işinize çok yarayacaktır.
Eğer ihtiyaç duyduğunuz şey yeni fikirler, farklı çıkarımlar ve perspektifler veya sağduyuysa; LLM’ler size yardımcı olamaz.